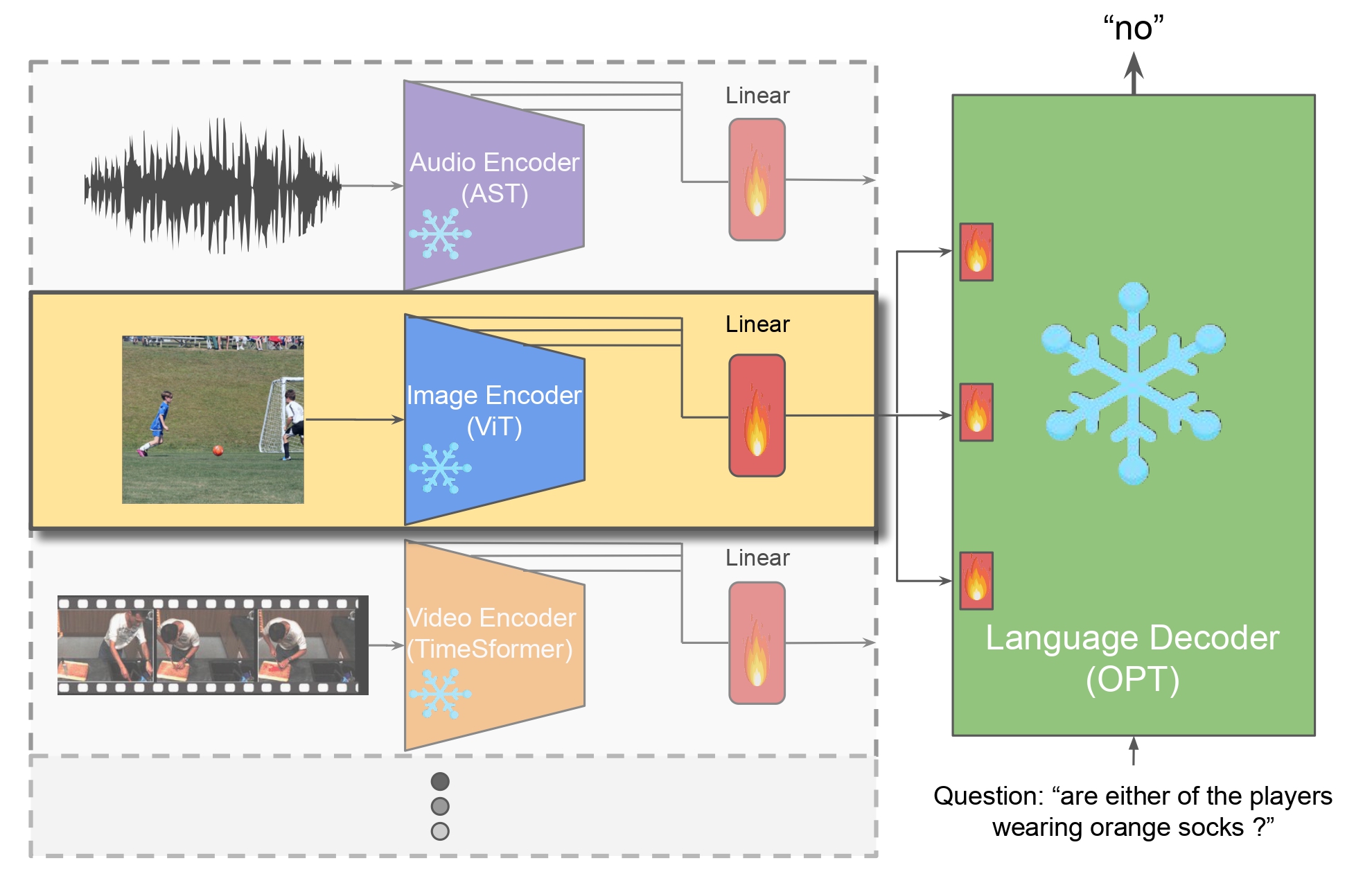
Large Language Models (LLMs) have so far impressed the world, with unprecedented capabilities that emerge in models at large scales. On the vision side, transformer models (i.e., ViT) are following the same trend, achieving the best performance on challenging benchmarks. With the abundance of such unimodal models, a natural question arises; do we also need to follow this trend to tackle multimodal tasks? In this work, we propose to rather direct effort to efficient adaptations of existing models, and propose to augment Language Models with perception. Existing approaches for adapting pretrained models for vision-language tasks still rely on several key components that hinder their efficiency. In particular, they still train a large number of parameters, rely on large multimodal pretraining, use encoders (e.g., CLIP) trained on huge image-text datasets, and add significant inference overhead. In addition, most of these approaches have focused on Zero-Shot and In Context Learning, with little to no effort on direct finetuning. We investigate the minimal computational effort needed to adapt unimodal models for multimodal tasks and propose a new challenging setup, alongside different approaches, that efficiently adapts unimodal pretrained models. We show that by freezing more than 99% of total parameters, training only one linear projection layer, and prepending only one trainable token, our approach (dubbed eP-ALM) significantly outperforms other baselines on VQA and Captioning across Image, Video, and Audio modalities, following the proposed setup,
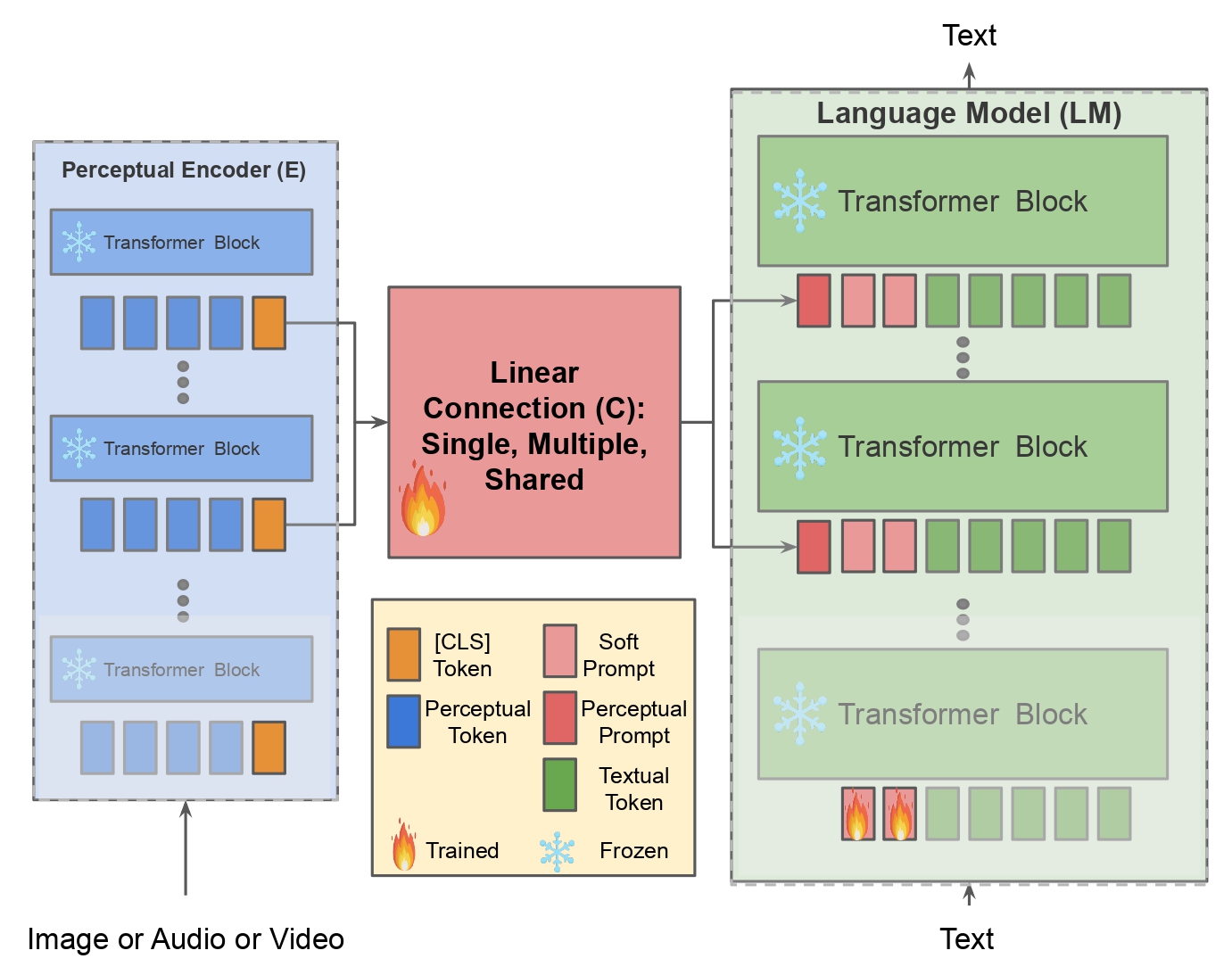
We adopt OPT models, which are autoregressive language decoders consisting of Self-Attention and Feed Forward layers.
They are trained with next token prediction objective on 180B tokens mostly in English and gathered from different datasets. Our model is based on the following main points:
Perceptual Encoders: we favor only unimodal models. For images, we use the vanilla ViT model pretrained for image classification
on ImageNet. For Video, we use TimeSformer that consists of a ViT-like model augmented with temporal attention and pretrained on kinetics.
For Audio, we adopt AST, a vanilla adaptation of ViT to digest spectrograms, that is pretrained on AudioSet.
Perceptual Prompt Injection: LMs are usually controlled via different textual prompts, such as questions and instructions.
Here, the LM is controlled by both the text and the perceptual encoders. Specifically, the projected perceptual tokens are prepended to the
textual tokens. Naively using all visual tokens, adds significant computation costs during training and inference.
To mitigate this, we consider only the [CLS] token of the perceptual encoders and prepend it to the text tokens.
This increases the total number of tokens by 1 which maintains almost the same inference speed.
Connecting Models with Cross-Modal Hierarchical Linear layers: when freezing the perceptual encoders and language models,
the minimal number of trainable parameters are those that amount to connecting these two models while adjusting the embedding dimensions in case
of a mismatch. Therefore, we base our approach on this constraint and train only one linear projection layer to connect both models.
To exploit the hierarchical representation encoded in pretrained models, instead of taking only the [CLS] token of the last output layer,
we take the [CLS] tokens from several layers of the perceptual model, and we inject these tokens into several layers of the LM (shared connection).
The tokens coming from early layers are injected earlier and are then replaced by those coming from deeper layers.
We favor only the deeper layers where the representations are more abstract and less modality-specific.
Moreover, using the same linear projection at different representation levels might not help
to capture the particularity of such a hierarchy, to this end, we also experiment with different linear layers for each
level.
Multimodal Adaptation with Parameter-Efficient Techniques: we explore several parameter-efficient techniques to ease
the adaptation to multimodal tasks. The main technique we use is Prompt Tuning: it consists of prepending trainable tokens or
Soft Prompts to the textual tokens input of the LM. This gives useful context to steer the model output.
Contrary to hard prompts that are manually engineered, this provides a more flexible and easier approach for task-dependant contextualization.
For the sake of efficiency, we prepend only 10 learnable tokens. We also experiment Adapters .
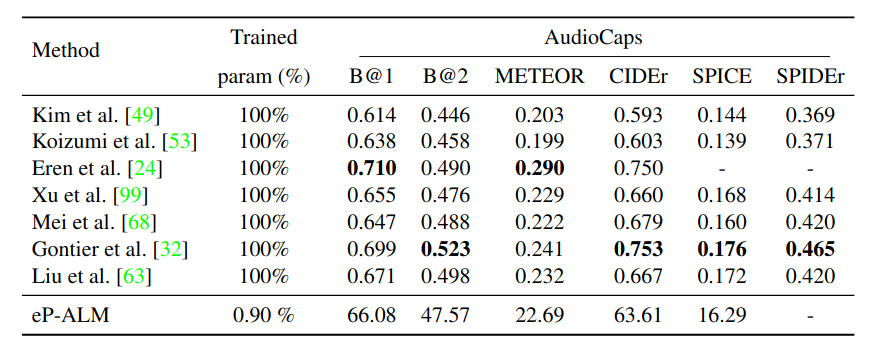
We compare with other end-to-end trained SoTA that takes only the audio signal as input and show that our approach is very competitive with previous work, showing the potential of efficient adaptation of LM for the audio modality.
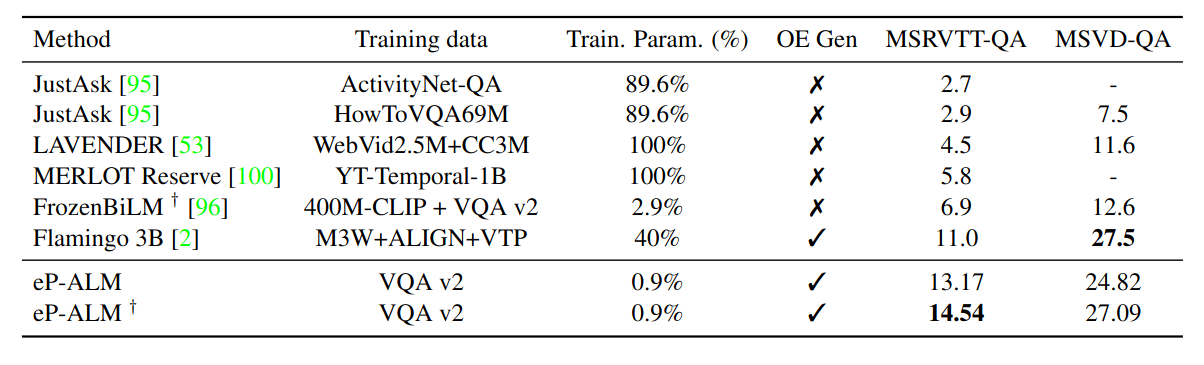
To explore the generalization of our approach, we evaluate on Zero-Shot for VideoQA, where the model is trained on a dataset different from the target one. Table below shows that eP-ALM, trained on VQA v2 (standard split), outperforms other approaches trained on significantly more data. Contrary to some of other approaches that cast the task as classification (similarity-based) or constrained generation through masking, considering only a subset of answers (1k or 2k), our approach is evaluated (with a character-wise comparison with the ground-truth) with unconstrained Open-ended Generation (OE Gen) and can generate answers with arbitrary lengths.
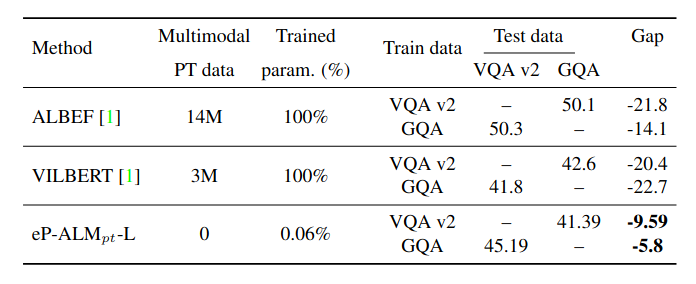
Here we investigate whether our parameter-efficient approach can perform well in OOD scenarios. To this end, we follow other approaches and train our model on the training set of a given benchmark, and evaluate it on the validation set of another benchmark, without multimodal pretraining. We measure the performance gap, i.e. the accuracy difference between a model trained on a different benchmark and the same model trained on the target benchmark. Table below shows that eP-ALM, which trains 0.06\% of total parameters, is very competitive in terms of OOD accuracy with other baselines, that train all model parameters and pretrain on large amount of data. This reveals that our parameter-efficient approach generalizes relatively well in OOD scenarios.
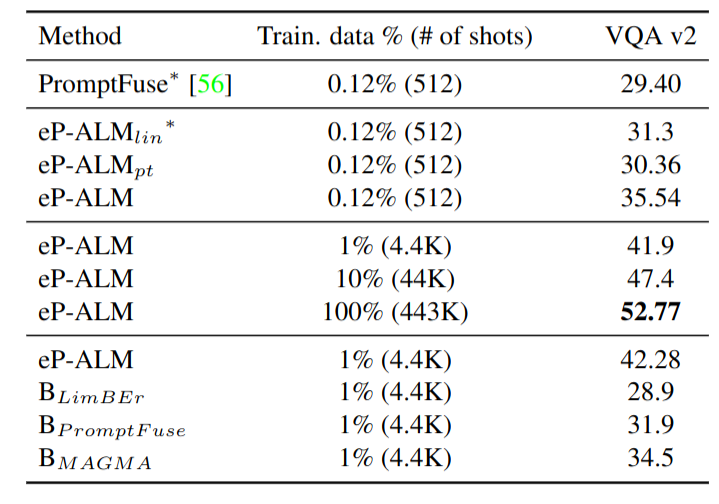
In this section, we investigate how data-efficient our model can be. To this end, we train on a very small portion (randomly sampled) from the VQA training set and evaluate on the validation set. Table below, shows the superiority of our approach over other baselines. Interestingly, we can achieve 80\% (41.9 vs 52.77) of the performance when training on 1\% of the data. This validates the approach on low resources scenarios and shows that, in addition to being parameter-efficient, our model is also data-efficient.
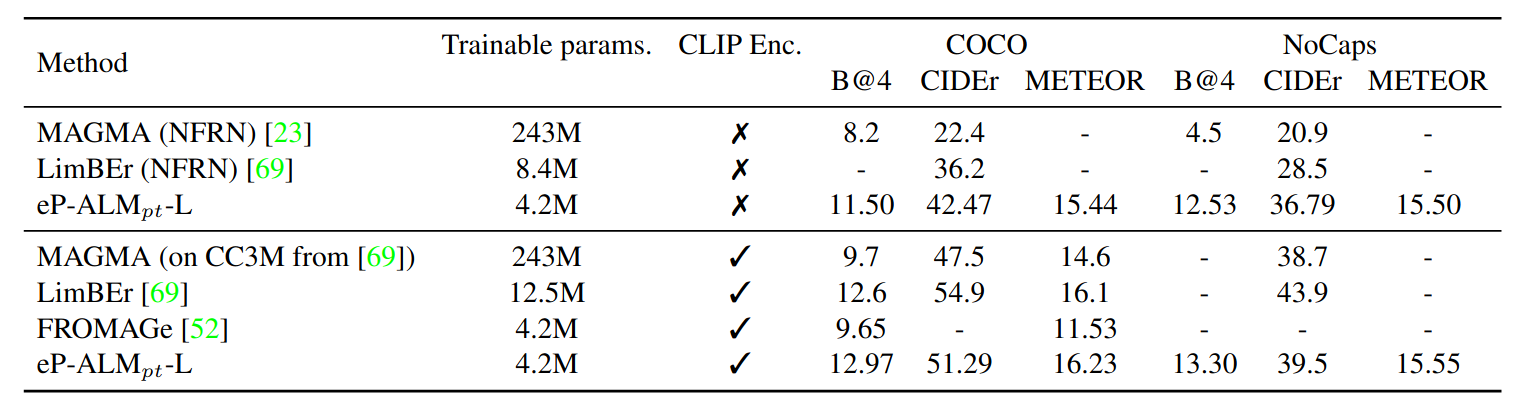
To contextualize the work, we compare eP-ALM to other SoTA that trains large number of parameters and most often with large-scale pretraining. Table below shows a comparison with both zero-shot (ZS) and Finetuning (FT) setups. The performance of eP-ALM is generally higher than ZS scores and still below FT ones. However, the performance gap with FT models, is smaller with the audio and video modalities.

We relax the constraints and evaluate the our approach on the pretrain-zeroshot setup. eP-ALM outperforms other comparable work on this setup.
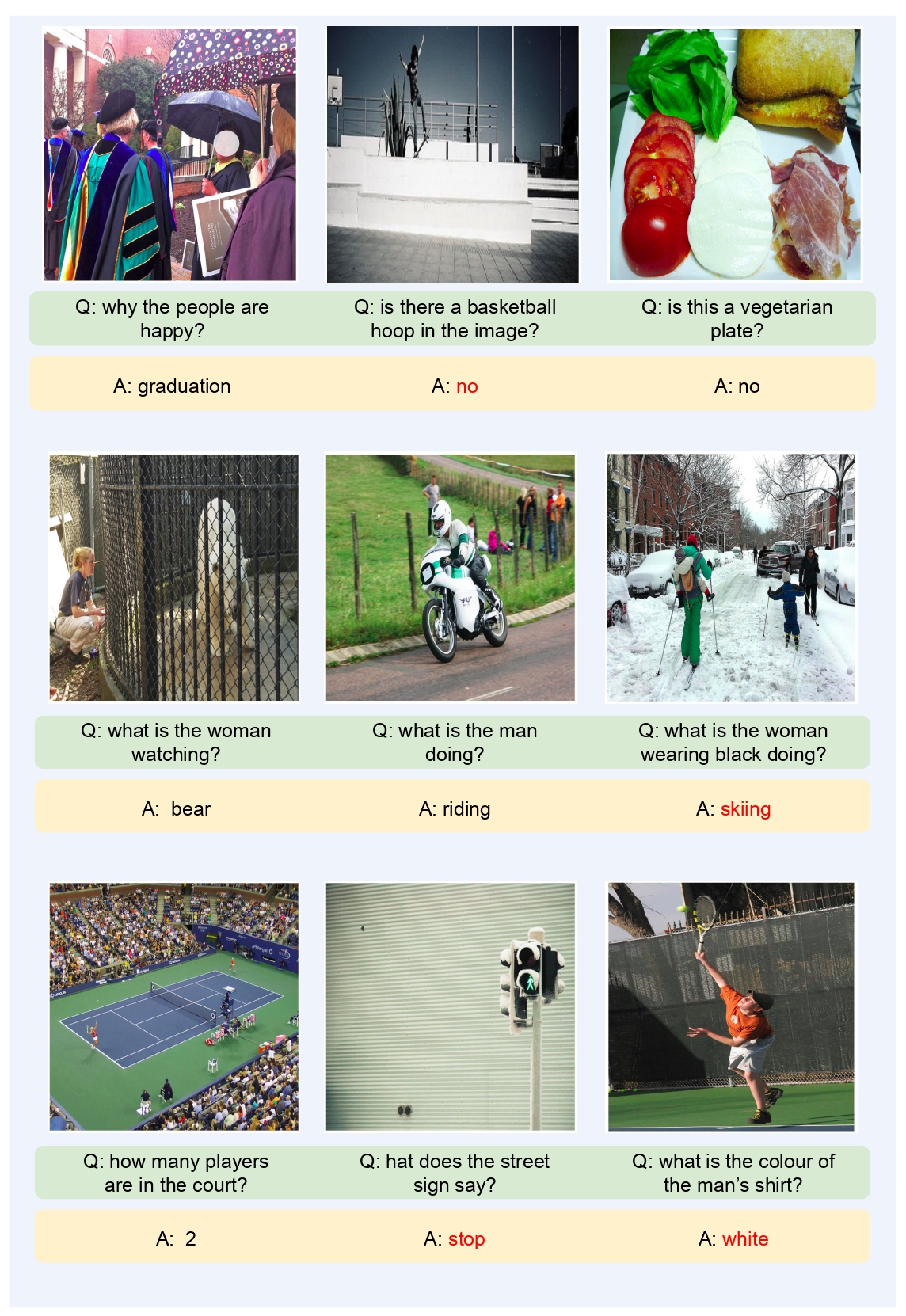
Some qualitative results on image captioning and VQA.

This work was partly supported by ANR grant VISA DEEP (ANR-20-CHIA-0022), and HPC resources of IDRIS under the allocation 2022-[AD011013415] and 2023-[AD011013415R1] made by GENCI. The authors would like to thank Theophane Vallaeys for fruitful discussion.
@article{shukor2023ep,
title={eP-ALM: Efficient Perceptual Augmentation of Language Models},
author={Shukor, Mustafa and Dancette, Corentin and Cord, Matthieu},
journal={arXiv preprint arXiv:2303.11403},
year={2023}
}